In a previous blog post, I introduced the BioAid project and discussed some of the motivations. I advise reading that post before reading this one. In this second installment, I aim to describe the algorithm architecture in technical detail and then discus some of its properties. This information is placed on my blog, allowing me to rapidly, and informally communicate some of the technical details related to the project while I gather thoughts in preparation for a more rigorous account.
Modeling the Auditory Periphery
The architecture of the BioAid algorithm is based on a computational model of the auditory periphery, developed in the hearing research laboratory at the University of Essex. This model has undergone refinements over a time period spanning four decades. Therefore, it would be unwise to describe it in detail in this blog post! However, an overview can be given that describes the processes most relevant to the design of BioAid.
The human auditory periphery (sound processing associated with the ear and low-level brain processing) is depicted in the abstract diagram below. The images represent the stages of processing in the auditory periphery that are modeled. The acoustic pressure waves enter the ear. The waveform in the diagram is a time domain representation of the utterance ‘2841’ spoken by a male talker. The middle ear converts these pressure fluctuations into a stapes displacement that drives the motion of fluid within the cochlear. In turn, this fluid motion results in the displacement of a frequency selective membrane, the Basilar membrane (BM), running the length of the cochlea. Along the length of the BM are:
- Active structures that change the passive vibration characteristics of the membrane in a stimulus dependent manner.
- Transduction units that convert the displacement information at each point along the membrane into an electrical neural code that can be transmitted along the auditory nerve to the brain.
The image plot on the right shows the simulated neural code. The output of the process is made of multiple frequency channels (y-axis), each containing a representation of neural activity as a function time (x-axis). The output resembles a spectrogram in its basic structure, although the non-linear processing makes it rather unique. For this reason, it is referred to as the auditory spectrogram.
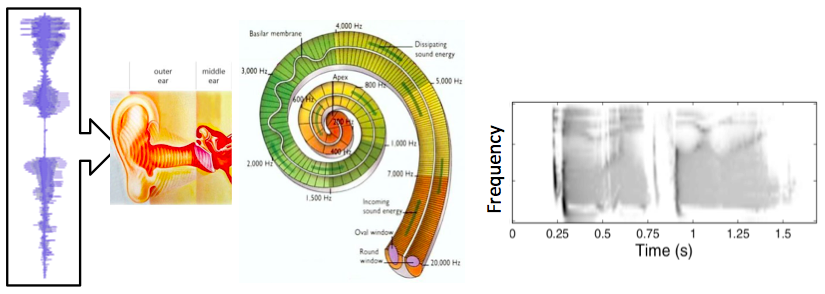
Diagram showing peripheral auditory processes. The input is shown on the left, and is processed to produce the output shown on the right.
This biological system can be modeled of as a chain of discrete sequential processes. In general, the output of each process feeds into the next process in the sequence. The model takes an array of numbers representing the acoustic waveform as its input. This is then processed by an algorithm that converts the acoustic representation to the displacement of the stapes bone within the middle ear. Following this, there is an algorithm that converts the stapes displacement into multi-channel representation of BM displacement along the cochlear partition. Next is a model of the transduction units, which convert the multichannel displacement information into a multichannel neural code representation. This is a representation of the information that would be conveyed by the auditory nerve to the brain.
The auditory model can then be used for various tasks. By making a model that can reproduce physical measurements, you can then use the model to predict the output of the system to all manner of different stimuli. For example, we know that the human auditory system is excellent at extracting speech information from noisy environments. By using the auditory model as a front end for an automatic speech recognizer, the modeler can investigate how the different components of the auditory periphery may contribute to this ability.
The basic dual resonance non-linear filterbank
There are a numerous models of cochlear mechanics. The dual resonance non-linear filterbank (DRNL) is the model developed within the Essex lab. BioAid is fundamentally a modified version of the latest version of the DRNL model.
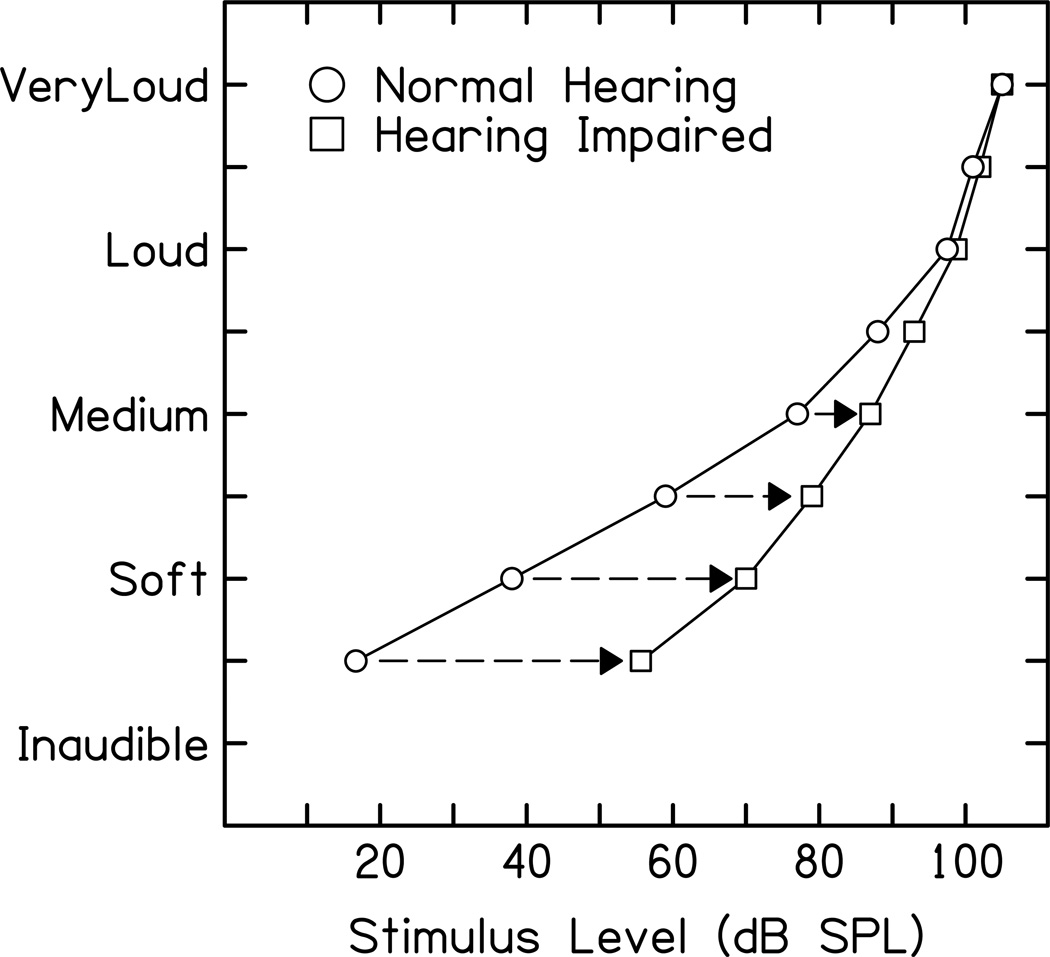
The DRNL model was originally designed to account for two major experimental observations. The first observation is the non-linear relationship of BM displacement relative to stapes displacement. This is shown by the diagram below. The basilar membrane displacement has a linear relationship with stapes displacement at low stimulus intensities. For a large part of the auditory intensity range (approximately 20 dB to 80 dB SPL across most of the audible frequency range), the relationship between stapes and BM displacement is compressive, i.e. the BM displacement only increases by 0.2 dB per dB increase in stapes displacement. At very high stimulus intensities, the relationship is linear, like at low intensities.
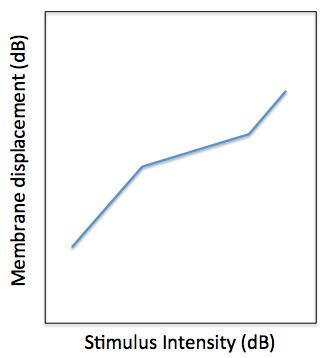
Illustration of the BM ‘Broken Stick’ non-linearity. The x-axis is the input stapes displacement and the y-axis is the output BM displacement.
The second observation is related to the relationship between the frequency selectivity of the BM with level. Each point along the BM displaces maximally at a specific frequency. Parts of the BM near to the interface with the stapes (base) respond maximally to high frequencies, while the opposite end (apex) responds maximally to low frequencies. For this reason, different regions along the basilar membrane can be thought of as filters. At low stimulus levels, the regions are highly frequency selective, so do not respond much to off-frequency stimulation. However, at higher stimulus intensities, the BM has a reduced frequency selectivity, meaning that the BM will be displaced by a proportionately greater amount when off frequency stimuli have high intensity. Not only does the bandwidth of the auditory filters change with stimulus intensity, but the centre frequency (or best frequency) also shifts.
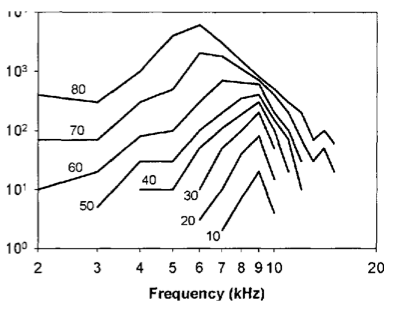
Illustration of level dependent frequency selectivity. Each line shows data from a different stimulus intensity. The x-axis is stimulus frequency and the y-axis is BM displacement for a fixed position along the membrane.
The DRNL is a parallel filterbank model, in that each cochlear channel along the BM is modeled using a an independent DRNL section. Each frequency channel of the DRNL model is comprised of two independent processing pathways. These pathways share a common input and the outputs of the pathways are summed to give the final displacement value for the location along the BM being modeled. The linear pathway is made of a linear gain function and a bandpass filter. The nonlinear pathway is made of an instantaneous broken stick non-linearity sandwiched between two bandpass filters. The filters are tuned according to the position along the BM being modeled. This arrangement is shown by the diagram below.
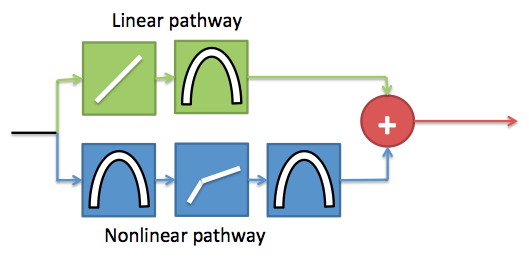
Schematic showing one frequency channel of the DRNL model
The linear pathway simulates the passive mechanical properties of the cochlear. Therefore, the output of this pathway in isolation would give the BM displacement if the active structures in the cochlear were not functioning. Conversely, the non-linear pathway is the contribution from the active mechanisms to the displacement. The 3-part piecewise relationship between BM and stapes displacement can be modeled by just summing the responses of the pathways. When performing decibel addition, the sum value is approximately the greater of the two values being summed. The output of each pathway is shown below, along with the sum total. The parameters are tuned so that the output of the model can reproduce experimental observations of BM displacement.
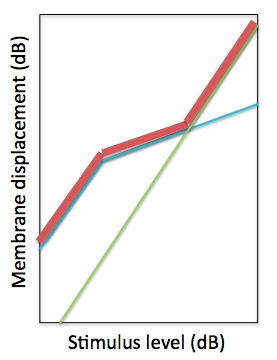
The green line is the input-output (IO) function relating stapes to BM displacement of the linear pathway of the DRNL model. The blue line is the IO function for the non-linear pathway. The red line is the decibel sum of the two pathways.
The DRNL model can also reproduce the level-dependent frequency selectivity data using this architecture. For this, the filters in the two pathways are tuned differently. As the level of stimulation increases, the contribution of the linear pathway becomes significant. By using different filter tunings, it is possible to make a level-dependent frequency response using this combination of linear filters.
The latest dual resonance non-linear filterbank
The active structures in the cochlear that give rise to the non-linear relationship between stapes- and BM-displacement are subject to control by a frequency-selective feedback pathway originating in the brain. When there is neural activity in this feedback pathway, the contribution of the active structures to BM displacement is reduced. The level of activity in the feedback network is at least partially reflexive: the feedback is activated when the acoustical stimulation intensity passes a certain threshold within a given frequency band, then grows with increasing stimulus intensity.
Robert Ferry showed that the result of neural activity in the biological feedback network could be simulated by attenuating the input to the non-linear pathway of the DRNL model. The cochlear and neural transduction processes have limited dynamic ranges, and there is some evidence to suggest that the feedback modulated attenuation may assist a listener by optimally regulating the cochlear operating point for given background noise conditions.
We subsequently went on to complete the feedback loop in the computer model. This was achieved by deriving a feedback signal from the simulated neural information to modulate the attenuation value. This complete feedback model can then adjust the attenuation parameter over time to regulate the cochlear operating point in accordance with changes in the acoustical environment. Data from automatic speech recognition experiments have shown that machine listeners equipped with the feedback network consistently outperform (i.e. correctly identify a greater proportion of the speech material) machine listeners without the feedback network in a variety of background noises.
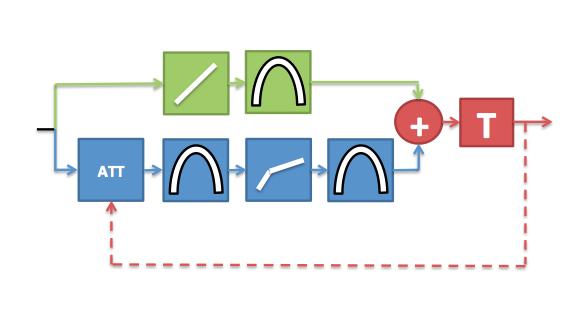
Diagram depicting the latest version of the DRNL model. The feedback signal is derived from the neural data after displacement to neural transduction stage (T). This feedback signal is used to modulate the amount of attenuation applied to the non-linear pathway over time.
Simulating hearing impairment
Some origins of hearing impairment are a result of a malfunction of certain parts of the auditory periphery. Some components of the auditory periphery are far more susceptible to failure (or reduced functionality) than others. These components can include a reduction in the function of the active structures in the cochlear that influence the BM displacement, and/or a reduction in the effectiveness of the transduction structures that convert BM displacement into neural signals.
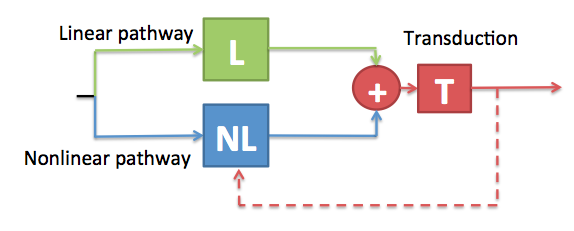
Simplified diagram of the DRNL model to highlight the impact of reduced peripheral component functionality on cochlear feedback.
Firstly, consider the case where the transduction units within a given channel are not functioning properly. Not only is there going to be an adverse effect on the quality of the information transmitted via this channel to the brain, but the feedback loop which is driven by the neural information will also not function optimally, thus compounding the problem.
Secondly, consider the case there the active structures are not functioning correctly. This will result in a reduced BM displacement for a given level of stapes displacement. The output of the transduction units will therefore be reduced, and so the feedback will be derived from a reduced-fidelity signal. To make things worse, any residual feedback signal will not be effective because the feedback signal modulates the action of the active components, which in this case are not functioning correctly.
BioAid is designed to artificially replace the peripheral functionality that may be reduced or missing in hearing impaired listeners. By simulating the non-linear pathway and feedback loop, BioAid can at least partially restore the function of the regulating mechanisms that help normal-hearing listeners to cope when listening in noisy environments.
BioAid Architecture
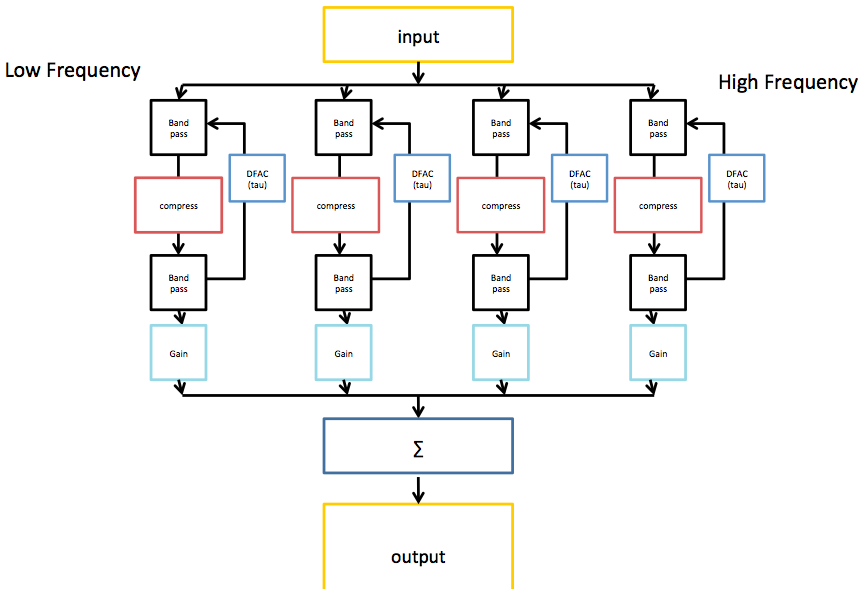
The image shows the architecture of the BioAid algorithm in block form. Only 4 channels are displayed for simplicity.
The first stage of processing in BioAid involves a decomposition of the signal into various bands. This is to coarsely simulate the frequency decomposition performed by the cochlea. The frequency decomposition performed in the BioAid app is done by a simple bank of 7 non-overlapping octave-wide Butterworth IIR filters centered at standard audiometric frequencies between 125 and 8000 Hz. When the signal is filtered twice (by first and second stage filters in the algorithm), the crossover points of each channel intersect at -6dB. This means that the energy spectrum is flat when the the channels are summed. The filters are each 2nd order. Even order filters must be used to prevent sharp phase cancellations at the filter crossover points. In the laboratory version of the aid, we have found some benefit to using an 11 channel variant of the algorithm, with additional channels between 500 and 1000, between 1000 and 2000, between 2000 and 4000, and between 4000 and 8000 Hz.
No phase correction network is used, as group delay differences between channels are not a primary issue when using wide bands with modest roll-off. For a higher frequency resolution, a filterbank with good reconstruction properties would be required. The optimum frequency resolution for this algorithm is still a research question. However, the really unique features of BioAid are related to the time domain dynamics processing that occurs within each band.
Within each band is an instantaneous compression process to simulate the action of the active components in the auditory periphery. Below the compression threshold, the input and output signals have a linear relationship. Above a certain threshold the waveform is shaped so that the only increases by 0.2 dB per dB increase in input level. In the code, this is implemented as a waveshaping algorithm that directly modifies the sample values, although it could be implemented equally effectively as a conventional side-chain compressor with zero attack and release time. Instantaneous compression is not commonly used in conventional hearing aid algorithms, as it introduces distortion. Normal hearing listeners find this distortion particularly unpleasant. However, we believe that some distortion may be useful to an impaired listener if it mimics that which occurs naturally in a healthy auditory system.
Following the instantaneous compression stage, the signal is filtered by a secondary bank of filters with the same transfer function as the first bank of filters. The instantaneous compression process introduces harmonic distortion that extends above the frequency range of the band-limited signal. It can also produce intermodulation distortion products that extend above and below the band. The secondary filter bank reduces the spread of signal energy across the frequency spectrum. Astute readers will notice that the secondary filtering means that the net compressive effect can no longer be described as instantaneous, but this is a discussion for the next blog post.
The output of the secondary filter stage is then used to generate a feedback signal. This is similar to the feedback signal implemented in the latest DRNL model, but for a reduction in computational cost, it is derived directly from the stimulus waveform (omitting models of neural transduction and low-level brain processes). We call this feedback signal the Delayed Feedback Attenuation Control (DFAC) when discussing it in the context of the hearing aid. This signal is used to modulate the level of attenuation applied to the input of each instantaneous compressor. The feedback signal has a threshold and a compression ratio like the instantaneous compressor, but it also has an integration time constant (tau) and delay parameter. Rather than modify the signal on a sample by sample basis, the DFAC integrates sample magnitude using an exponential window. This signal supplied to the integrator is delayed by 10 ms (using a ring buffer) to simulate the neuronal delay measured in the biological analogue of this process. The compression threshold value is then subtracted from the integrated value and multiplied by the compression ratio to give an attenuation value for the next sample.
The implementation of the algorithm in the app is mono. However, the algorithm code can be used in a stereo configuration (we use a stereo configuration when evaluating the algorithm in the lab). When a stereo signal is supplied, the DFAC attenuation is averaged between left and right channels. This means that the attenuation applied is identical in left and right channels within a certain frequency band. This linked setup prevents the DFAC from scrambling interaural level difference cues that might be useful to the listener. In contrast, the instantaneous compression processing is completely independent between left and right channels.
In a nutshell, each channel of BioAid is a laggy feedback compressor with an instantaneous compressor sandwiched between its attenuation and detection stages. This simple arrangement is completely unique to BioAid, and certainly quite unlike the automatic gain control circuits found in standard hearing aids.
After the secondary filtering, we depart from our adherence to physiological realism in the main signal chain. All of the processing up to this point has been focused on reducing the signal energy. To make sounds audible to hearing impaired listeners, a gain must be provided in the impaired frequency regions. This is done on a channel-by-channel basis before the signals from each of the channels are summed and then presented to the listener.
Summary
In this blog post I have described the architecture of the DRNL filterbank and how the non-linear pathway of the DRNL model forms the core of the BioAid algorithm. In the next post I will describe the unique properties of this algorithm.